This app is meant to help high school students in their final two years of study prepare for the admission exam of the University of Medicine and Pharmacy Bucharest.
During the admission exam, candidates are expected to answer 100 questions, of which 40 can be about organic chemistry, in two and a half hours. Based on their performance, some of the candidates will go on to study medicine for the next six years; a part of them will have to pay a yearly tax, while a minority of students will even receive a monthly merit bursary.
Stack
Context #
My mother has been teaching biochemistry at the university and has been working with college students wanting to become medics for the past 30 years. She has always wanted to simplify the information and make it as logical as possible while also benefitting from digitalisation in a country that is not actively looking to integrate technology in the public education system.
Wanting to change the status quo, she allied with a colleague of her and they asked me if it was possible to build a simple web app where they could create their own lessons in digital format. The goal is for their students to always have the information with them by using a phone or a laptop to access the app anytime.
Requirements #
After a few conversations with mum and her colleague, the requirements were simple to establish; the solution had to be:
- Self-managed — the teachers should be able to manage all the students and assigns them into different tutoring groups.
These groups then receive access to the different lessons, based on their actual progress in the tutoring sessions. - Semi-private — without an account, nothing can be seen from the exterior — the website should not be indexed by Google or other search engines.
- Mobile-first — almost all students are between 17 and 19 years old;
Having straightforward access to the learning material at all times from just their smartphones is key to their success at the admission exam. - Simple to maintain — the app should allow teachers to author their content and lessons, and ocassionally make use of images and PDF files. Throughout the academic year, my involvement in maintaining the app should also be minimal.
Tech stack #
Just like with most side projects, I was especially interested in some parts of the stack; thus, some parts were over-engineered, like the back-end, while others were built minimally.
Backend #
My goal was to provide a solution to this problem but also to experiment a bit more with technologies I’m interested in. I wanted to see how GraphQL works in more detail and implement it myself from start to finish, to better contrast it with the familiar REST model.
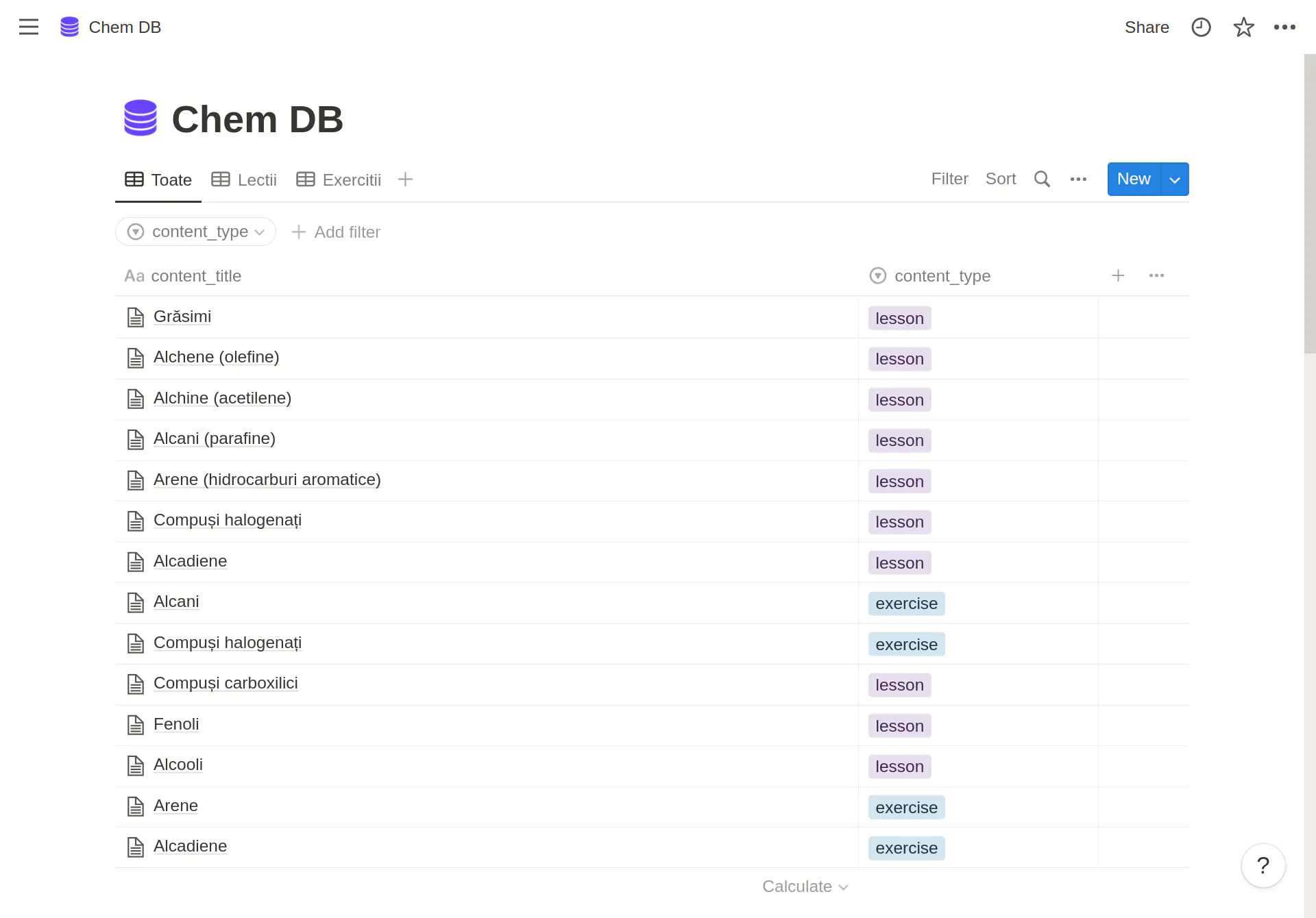
- CMS — Notion
- This was the first decision made, since the teachers need a simple, user-friendly way to author content
- Notion provides API access for free and it just an amazing tool that I use every day
- I read good things about their API and data model from the community and their technical blog
- API — NestJS, TypeScript, GraphQL, TypeORM
- Application logs are being sent to CloudWatch directly through Winston
- The backend code is unit tested, and there are a couple of E2E tests performed on the API
- The unit & E2E tests also run on the CI pipeline, since database containers can be deployed temporarily with GitHub Actions as service containers
- Data
- MySQL — I chose to use a relational DBMS because I was curious to see how an ORM in the JS/TS ecosystem compares with other projects such as .NET’s Entity Framework or Laravel’s Eloquent ORM.
- TypeORM makes for a very enjoyable development experience, and is quite powerful in combination with its CLI and the native TypeScript support for data types (via annotations).
- A NoSQL document database such as AWS DynamoDB or MongoDB would’ve been a better fit, since Notion’s SDK returns JSON and that could’ve simplified the block aggregation process.
- Redis — stores user session tokens and is also used by Bull to facilitate the asynchronous job queue.
- Notion — stores the database containing all the content
- MySQL — I chose to use a relational DBMS because I was curious to see how an ORM in the JS/TS ecosystem compares with other projects such as .NET’s Entity Framework or Laravel’s Eloquent ORM.
Frontend #
- The frontend was built using NextJS; it is using Apollo GraphQL to interact the GraphQL API and hold the state.
- NextJS processes
the JSON it gets from the API and renders it as an array of JSX elements, depending on the type of the blocks it encounters.
- This algorithm is recursive, since, by design, blocks can have children blocks which also need to be rendered however many levels deep.
- It features:
- light & dark themes
- internationalisation (Romanian & English)
- a simple filter for the content type
- a search bar to quickly find content by title
- a mobile-friendly admin panel to manage students, groups, and assign content to groups
DevOps #
Infrastructure
- CDK is used to provision the infrastructure, with almost everything automated; there are two environments: dev (
dev.cduta5.com, usually deployed only when needed, to avoid costs) & prod (cduta5.com). - The environments are mapped to different AWS accounts as per AWS best practices, using AWS Organizations.
CI/CD
- There are two EC2 instances required; one holds the databases (MySQL & Redis) and the other one the backend NestJS, the frontend NextJS, and a reverse proxy using Nginx.
- All containers are uploaded to AWS ECR.
- ECS is used, in combination with reserved EC2 instances (not Fargate), to manage the containers and keep them up.
- GitHub Actions tests, builds, and deploys the containers to ECS.
Network
- Each EC2 instance belongs in a separate security group; the two SGs reference each other to allow for access from the app to the databases.
- The traffic between the instances is kept in the VPC; a Route53 private hosted zone facilitates this.
- SSM Session Manager provides secure SSH access to the instances if anything ever needs to be investigated.
Challenges #
Notion ↔ MySQL synchronisation #
With lessons that contain over 100 nested child blocks, it is impossible to ensure good performance without some pre-processing made for every page.
This synchronisation process involves combining all nested children under a root parent block, resembling a tree-like data structure, that’s serialised as JSON and stored in the content table in the database.
This was by far the most interesting technical aspect of this project and the most important one; it is a totally asynchronous process, initiated by the syncNotionJob() function.
This process is scheduled to run every 15 minutes, which was the ideal gap that we found between two syncs.
However, Notion’s API is heavily rate limited to just 3 requests per second — this sounds like a lot, but it can quickly become insufficient when you already have over 500 blocks. The full synchronisation process from an empty database table takes around 5 minutes currently, while also maxing out the rate limit.
Every API request is abstracted in an async job and placed onto a queue that matches this rate limit, so staying under the limit is very simple in this case.
Diffing algorithm
To keep the state in sync between Notion’s database and the content table in MySQL, the IDs of the root blocks are compared. Those that are not found in MySQL represent pages that need to be fetched, and later on, aggregated. Similarly, the IDs that are present in the content table, but not on Notion, denote content that has to be removed (notion-api.processor.ts
performs exactly this).
However, Notion’s API also presents a limitation here, because the parent block’s lastUpdatedAt property does not also reflect the lastUpdatedAt of its children blocks.
This means that all common pages (present in both Notion & MySQL) still need to be updated, since the root parent’s lastUpdatedAt cannot be trusted on its own.
Another implication of this limitation is that the sync process must run regularly and re-fetch all the parent and their children blocks recursively. This explains the 15 minutes gap set between two syncs from earlier.
Whenever a page has to be created or updated, the process starts from the root parent block. It then recursively fetches all its children and saves every block in the notion_block table.
Block aggregation
With all blocks required for a page to render now present in the notion_block table, it is now time to attach all child blocks to their respective parents, and store the resulting content as JSON in the content table.
This recomposition (or aggregation) process roughly does the following:
- Starting from the initial parent block, the job recursively takes all the children from the
notion_blocktable and adds a children property on the parent object.- In case a block is not present in the
notion_blocktable oris_updatingstill, the job will fail itself and rely on the queue, which is set up to retry an aggregation for a page for up to 4 times with a delay between each attempt.
- In case a block is not present in the
- The resulting tree is then stored in the
contenttable as JSON, ready to be served as-is to the frontend. - When a page is requested, the frontend will generate an array of JSX elements based on the JSON tree and render that to the end user afterwards.
Refreshing pages
This feature was heavily requested since it is very useful when authoring new content, because it allows the teacher to quickly iterate while also seeing how the content looks on the live website.
To achieve this, I have made sure to re-use as much code as possible to trigger a refresh for a particular page only. A button is now visible to all admins underneath the title of the page.
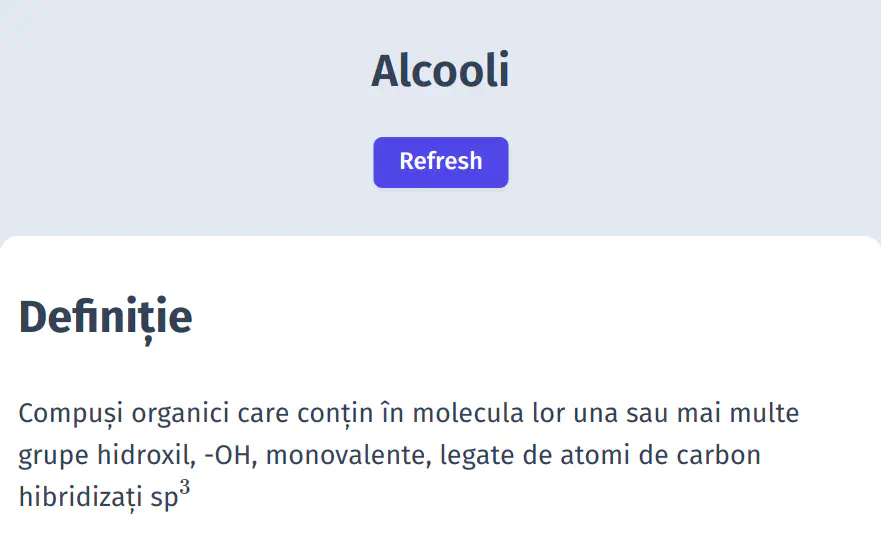
Without this functionality, teachers would have to wait for up to 15 minutes for the next scheduled sync to happen, which would greatly impede their ability to digitalise as much content as quickly as possible.
Running on ARM64 #
There are more and more consumer-grade computers that run on ARM these days; Apple have started the trend by ditching their Intel partnership after having developed their own in-house chips based on the ARM architecture.
In October 2022 Microsoft have also announced Project Volterra
, the Windows Dev Kit that’s based on ARM and is meant to encourage devs to port their Windows applications to ARM64.
On the cloud, ARM is not a novelty anymore; AWS has already introduced the 3rd generation of their Graviton ARM processors, promising even better compute performance and cost savings at the same time.
I wanted to see whether I could somehow port the app and all its dependencies to ARM and make use of the new t4g series of EC2 instances. Fortunately, docker has added support for multi-arch images
with its buildx tool in 2019. After a few fiddly npm packages and choosing the right base image, I was able to deploy the containers on t4g servers.
The biggest disadvantage is that the build time rose from under a minute to around 8 minutes when the CI/CD pipeline builds it now, since buildx has to convert every instruction from x64 to ARM64 under the cover, but that’s to be expected.
Possible improvements #
- Better secrets management by integrating SSM Parameter Store (or Secrets Manager) for keys and tokens.
- Generating the pages with NextJS (NextJS Incremental Static Regeneration
) every 15 minutes instead of on every request.
- Doing this should save some resources since most of that computation is based on older data that’s updated every 15 minutes
- Hosting the images and PDFs on own S3 buckets instead of relying on Notion
- Currently, Notion hosts all the assets attached to the pages.
- Notion’s API provides pre-signed S3 URLs that are only valid for 1 hour; this validity period cannot currently be changed.
- Hosting everything myself could allow me to perform a
syncNotionJob()much more rarely. - With the refresh functionality also implemented, it would ensure content freshness, while also minimising network requests to Notion’s API.
Conclusions #
The app has already been in production for 3 months and, so far, the feedback has been positive; the students like the minimalism of the website, since the main area of focus is the content itself, not what facilitates it.
Being able to use ECS with EC2 reserved instances means the whole solution is around £10 per month per environment for the 2 EC2 instances and the other AWS services used (such as DNS, CDN, network traffic, logs, backups, etc…).
Currently, the app serves around 100 students which log in at different times of the day from various user agents (indicating the students are using their smartphones to access the site at any time they like, just as intended).
Hopefully this initiative will help more people get into medicine, as the Romanian national health system needs skilled doctors now more than ever. 🤞